秒杀问题
秒杀问题
Jaron秒杀问题
为什么订单表的id不设置成自增:
id规律性太明显:容易被人猜到
单表数据量限制:大量的订单一定会多个表维护,每个表在自增的时候都会从小到大增加,会出现重复id,订单不能有重复id情况
全局ID生成器
雪花算法(Snowflake Algorithm)是由 Twitter 开发的一个用于生成全局唯一标识符(GUID)的系统。这个算法能够在分布式系统中生成唯一的、有序的64位整数ID,非常适合需要高频率创建记录的大型在线服务。
雪花算法的结构
雪花ID是一个64位的长整数,从最高位到最低位,分为以下几个部分:
第1位:未使用,由于整数一般是正数,因此最高位是0。
时间戳部分:通常是41位,用来记录时间戳,精确到毫秒。41位时间戳可以使用约69年。
工作机器ID部分:通常分为5位数据中心ID和5位机器ID(也可以根据实际需求调整这两个部分的位数),可以最多支持2^(5+5)=1024个节点。
序列号部分:通常是12位,每个节点在同一毫秒内可以生成4096个ID。
雪花算法的特点
高效性:生成ID的过程完全在内存中进行,相比基于数据库的自增ID,性能非常高。
趋势递增:由于高位是以时间戳进行的排序,生成的ID自然是按时间趋势递增的,这对于数据库插入操作是有利的(因为大部分数据库是基于B+树的索引,递增的ID可以最大化利用索引的性能)。
无需依赖数据库:完全不需要进行数据库的I/O操作,可以由应用程序独立生成ID,减轻了数据库的压力。
分布式系统中无冲突:通过自定义的数据中心ID和机器ID,即使是在物理位置分散的系统中,也能保证生成的ID是全局唯一的。
应用场景
雪花算法适用于任何需要生成全局唯一ID的场景,特别适合于服务架构较为复杂、服务分布广泛且需要生成大量ID的系统,如在线购物平台、社交网络等。
库存超卖问题
库存超卖问题是电商和零售等领域中常见的问题,指的是由于库存管理不准确或并发控制不当,导致实际卖出的商品数量超过实际库存量的情况。这个问题在高并发环境下尤为突出,特别是在促销或大型折扣活动期间
在多线程情况中,有其他线程在线程1查询库存后,扣减数量前进行库存的查询,就会出现库存超卖问题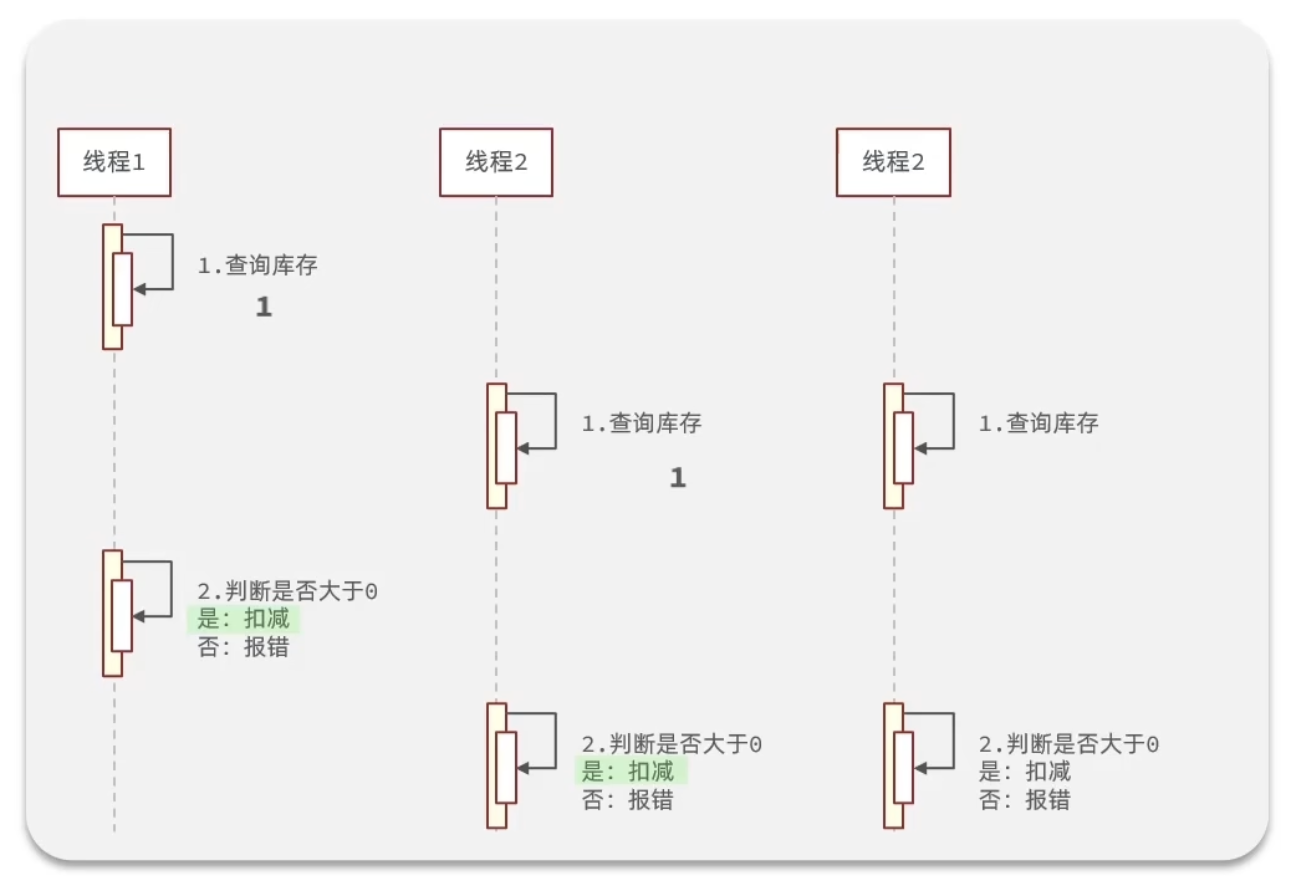
解决库存超卖问题的策略:
- 乐观锁:
使用乐观锁可以在不阻塞读操作的情况下管理库存更新。通常,这涉及到检查在读取库存数量和实际更新之间是否有其他修改发生(通常使用版本号或时间戳)。
如果在这段时间内库存被修改,则更新操作将失败,并可提示用户重新操作或直接拒绝订单。
- 悲观锁:
在处理库存更新时直接在数据库上锁定记录,直到当前事务完成。这可以确保一次只有一个操作能够修改库存数据。
悲观锁能有效防止超卖,但可能会降低系统的并发能力,增加响应时间。
- 分布式锁:
在分布式系统中,使用分布式锁来控制对库存数据的并发访问。
这种方法适用于多个服务或多个系统实例需要共享库存数据的场景。
乐观锁解决方案: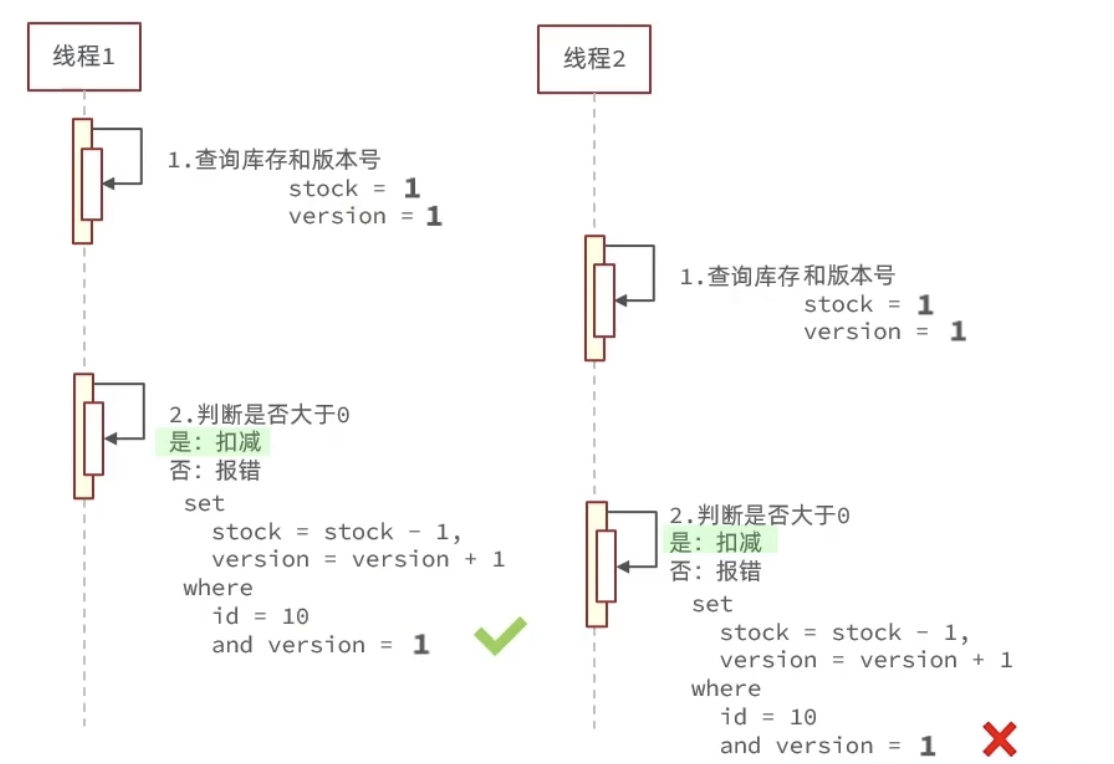
利用数据库本身的行锁,当我们想要减库存的时候,查一下版本号是否发生变化,如果有变化就放弃更改
我们可以优化一下,直接使用stock库存数作为版本号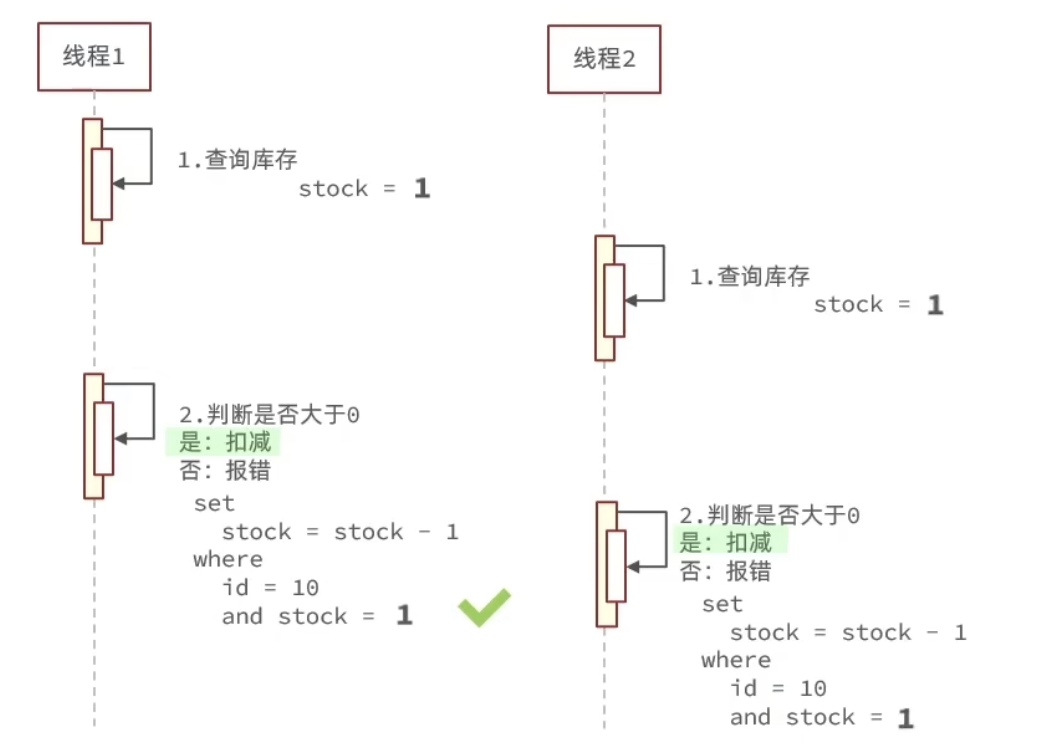
但是如果是按照这种方式,判断当前库存数量是否和检查时的库存数量一样(检查当前库存数量为10,当更改数据库的时候还是判断现在库存数量是否为10),会造成很多请求失败的情况,效率非常低,这是因为会有非常多的线程同时修改同一件库存,但是因为我们使用了乐观锁,最终只有一个请求能成功,所以我们之间把条件改成当库存数量大于0我们就允许更改数据库,而不是严格的等于之前查看的库存数量
一人一单问题
为了防止优惠券全被黄牛抢走,我们需要设计一个人只能买一张的功能
1 | // 1.一人一单逻辑 |
但是这样写同样会在多线程情况下出现问题,如果同时有100个线程查询count,那么都会得到0,一个人就又可以买多张优惠券
于是我们可以把这段代码放进一个方法内,在方法上加锁
1 |
|
但是这样写锁的粒度太大了,我们其实没必要锁方法,我们直接锁userId就行,也就是说锁同一个人,防止他多买就可以了
1 |
|
这里注意,我们单纯的锁userId.toString()是不可以的,因为toString()底层是新建了一个String对象,那么即使userId是一样的,但是由于是新new的对象,我们也锁不上同一个userId,所以要用.intern()方法先去字符串常量池获取,这样就能正常锁住了
但是,由于事物的提交是在createVoucherOrder函数运行完之后,而我们锁是在synchronized关键字包含的代码运行完之后就释放了,那么此时就会出现问题,即锁释放了,其他线程可以进来,进行了查询count数量,但是由于上一次的事物并没有提交,所以依然会存在多卖问题,所以我们锁的粒度太小了
因此我们需要锁住这个函数
1 | synchronized (userId.toString().intern()) { |
tips:这个锁与直接加在方法上的锁(public synchronized Result createVoucherOrder(Long voucherId))是不一样的,加在方法上,任何线程访问此方法都必须先获得锁,而synchronized块锁定字符串的版本只有当操作相同的userId时,线程才会被阻塞
当我们在synchronized块中直接调用createVoucherOrder方法时,调用是通过this关键字发起的。在Java中,this指的是当前对象本身,而不是Spring生成的代理对象。因此,这种调用方式绕过了Spring的代理机制,导致@Transactional注解不生效。因此在同一个类中的方法互相调用时,要使用Spring框架的AopContext.currentProxy()来获取当前代理对象,并通过它来调用事务方法。这需要在Spring配置中启用exposeProxy=true。
1 | synchronized (userId.toString().intern()) { |
分布式锁
当我们用以上代码,并部署到集群服务器中,还是会出现问题,因为我们有多个JVM,每个JVM分别维护了一个锁监视器,此时同一个用户的请求可能分到了不同的JVM中,就又出现了线程安全问题
Redisson
配置Redisson客户端
1 |
|
使用Redisson分布式锁
1 |
|
Redisson可重入锁原理
Redisson 可重入锁(Reentrant Lock)是一种分布式实现,允许同一个线程多次获取相同的锁而不会发生死锁。这种锁的实现是基于 Redis,利用 Redis 提供的原子操作来确保锁的安全性和一致性。这里是一些关于 Redisson 可重入锁的关键实现细节:
1. 数据结构
Redisson 的可重入锁主要使用 Redis 的哈希表来存储锁的状态信息。通常包括:
锁的持有者(线程ID):标识哪个线程持有了锁。
重入次数:一个计数器,记录锁被同一个线程重复获取的次数。
2. 加锁机制
当线程尝试获取锁时,Redisson 会执行以下操作:
检查锁是否已存在:Redisson 通过检查 Redis 中是否存储了锁的信息来确定锁是否已被其他线程持有。如果锁不存在,线程将创建锁并设置重入次数为1。如果锁存在并且当前尝试加锁的线程是锁的持有者,则增加重入次数。
设置锁的过期时间:为防止死锁,Redisson 会设置一个过期时间。
3. 解锁机制
解锁时,Redisson 会减少锁的重入次数:
减少重入计数:如果当前线程持有锁,并且重入次数大于1,Redisson 会减少重入次数。
释放锁:如果重入次数降至0,则完全释放锁。这通常涉及删除 Redis 中存储的锁信息,或者重置相关的数据。
Redisson的锁重试机制
在Redisson中,当一个线程尝试获取一个已被其他线程占用的锁时,它的行为遵循以下步骤:
- 等待锁释放消息:
当线程发现锁已被占用时,它不会立即进行重试。相反,它会订阅一个与锁相关联的特定频道,等待锁的释放消息。
这种基于消息的等待机制减少了无效的轮询,从而降低了资源消耗。
- 超时处理:
线程在等待锁释放的消息时会设置一个超时时间。如果在这段时间内没有收到锁释放的消息,或者等待时间已经耗尽,线程将停止等待并返回false,表示获取锁失败。
如果在最长等待时间内收到了锁释放的消息,线程还会检查剩余的等待时间(因为获取锁还需要时间,所以如果剩余时间-获取锁时间小于0还是会返回false)。如果剩余时间小于或等于零,同样会返回false。
- 重新尝试获取锁:
如果还有剩余的等待时间,并且收到了锁释放的消息,线程将再次尝试获取锁。
如果获取锁失败,线程将再次等待新的锁释放消息。这一过程会循环进行,直到成功获取锁或超时。
- 锁释放信号处理:
- 当持有锁的线程释放锁时,它会在相关频道发布一个释放消息。所有等待这个锁的线程会接收到这个消息,并根据上述逻辑处理重试或放弃。
- 信号量获取:
- 在多次重试中,线程可能需要依赖于信号量来正确管理多个线程之间的等待状态。这是通过使用Redis的发布/订阅系统实现的,保证了当锁释放时能够及时通知等待的线程。
看门狗机制
在Redisson中,看门狗(Watchdog)的功能尤其重要,尤其是在处理锁的超时释放方面。看门狗的主要任务是确保即使在发生异常或运行过程中的延迟时,持有锁的线程仍能保持锁的所有权,直到它们完成其关键部分的执行。这种机制对于防止数据一致性问题至关重要。
锁超时与自动续期
Redisson的锁实现通常包括设置一个明确的锁持有时间,即锁的“生存时间”(TTL)。这个时间是为了防止死锁和资源无限期占用的一种安全措施。在分布式系统或多线程环境中,可能会因为各种原因(比如JVM暂停、系统负载高、网络问题等)导致持有锁的线程未能在预期时间内释放锁。如果没有适当的机制,一旦锁的TTL到期,该锁就会自动释放,无论持有锁的线程是否已经完成其任务。
看门狗的自动续期功能
为了防止这种情况发生,Redisson的看门狗自动执行以下任务:
- 自动续期:
- 当线程成功获取锁时,看门狗会启动,并监控锁的状态。看门狗会在锁快要到期时自动更新其过期时间,通常设置为锁的最初超时值的一半。这样可以确保只要线程还活跃,锁就不会因为时间到期而被释放。
- 守护线程:
- 看门狗以守护线程的形式运行,这意味着它的生命周期依赖于启动它的JVM实例。如果应用程序停止或重启,守护线程也会相应停止,不会无限期地运行。
- 故障安全:
- 如果持有锁的线程因为任何异常终止,或者由于某些原因未能续期锁,看门狗也将停止续期。这意味着锁最终还是会到期并释放,其他线程可以尝试获取锁并继续执行。
MultiLock
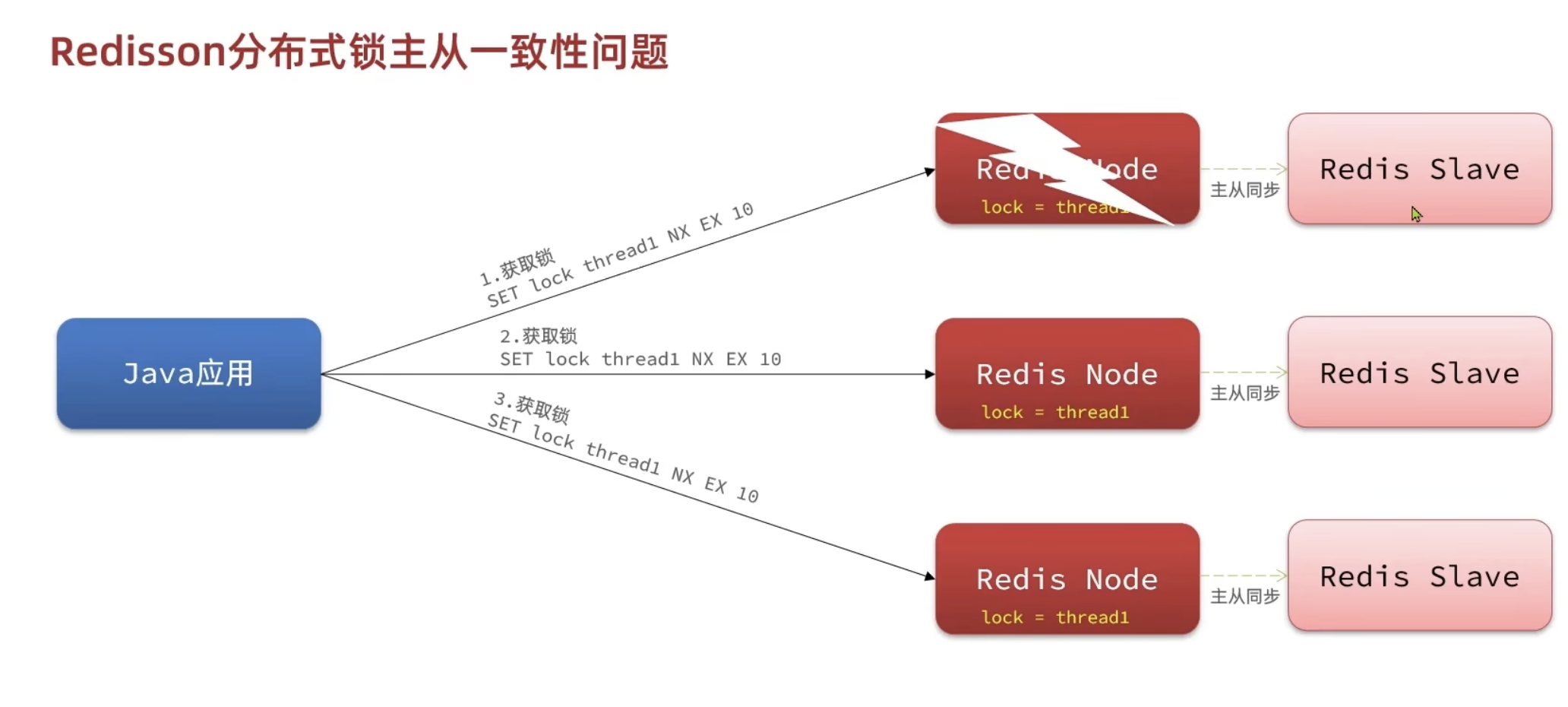
主从一致性问题通常发生在Redis使用主从复制架构时。在这种架构中,主节点负责处理所有的写操作,而从节点则处理读操作。为了保持数据的一致性,从节点需要定期从主节点同步数据。然而,由于主从节点可能部署在不同的机器上,数据同步过程可能会存在一定的延迟。如果在数据同步过程中主节点突然出现故障,Redis会从现有的从节点中选举出一个新的主节点。这时,如果有数据尚未来得及同步到新晋升的主节点,比如某些锁的信息,那么这些信息将会丢失。结果就是,其他线程尝试获取这些原本应该被锁定的资源时可能会意外成功,从而引起线程安全问题。
这种情况下,即使系统迅速恢复了服务,但由于锁信息的丢失,还是可能导致数据不一致或其他线程安全相关的问题。
于是我们可以使用联锁,只有如下将三个锁都拿到了才能成功获得锁,如果其中一个宕机了,但是从节点补上的时候丢掉了锁的信息,即使另一个线程拿到了这个从节点的锁,也无法从另外两个正常的主节点拿到锁,从而获取锁失败
总结
- 不可重入Redis分布式锁:
- 原理:利用setnx的互斥性;利用expire设定锁超时,释放锁时删除对应键
- 缺陷:不可重入、无法重试、锁超时的失效
- 可重入的Redis分布式锁:
- 原理:利用hash结构,记录锁定标识和重入人次数;利用watchDog延续锁的时间;利用信号量控制并防重试等待
- 缺陷:redis宕机引起锁失效问题
- Redisson的multiLock:
- 原理:多个独立的Redis节点,必须在所有节点都获得锁后,才算获取锁成功
- 缺陷:运维成本高、实现复杂
异步秒杀优化
我们可以将原来的整个从检查到下单在单线程完成的工作,分成两个线程做,一个只判断是否有购买优惠券的资格,够资格添加到消息队列内,让另外的线程去完成下单功能,这样性能会更好,将本来串行执行的业务分给了两个线程取执行
而且原来需要查询数据库来判断是否有下单资格,可以用redis实现,减少数据库查询操作
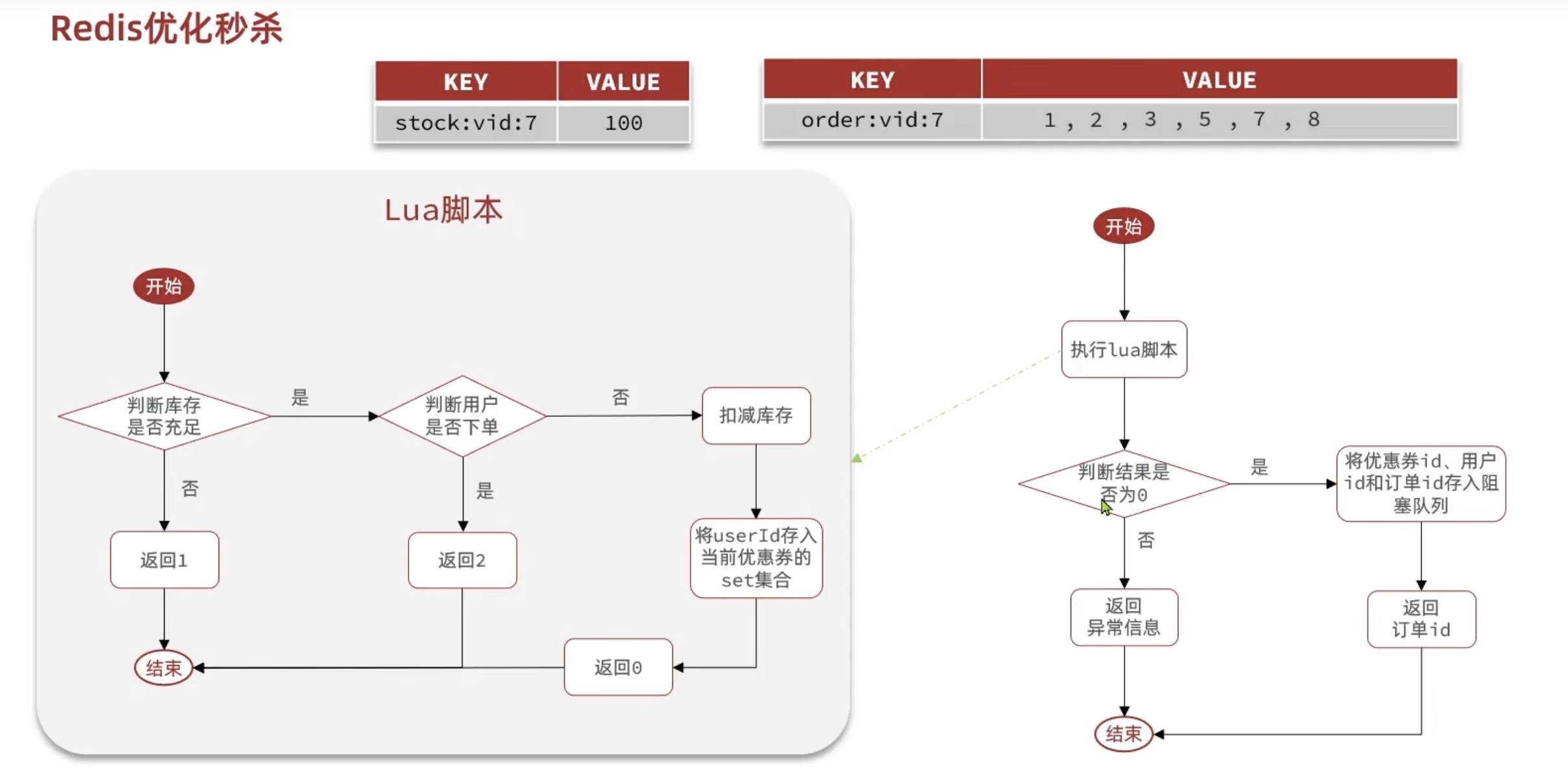
下单功能可以用阻塞队列完成
1 | //阻塞队列 |
消息队列
但是基于阻塞队列的异步秒杀实际上存在两个问题,一个是 JVM 的内存限制,一个是阻塞队列中的数据可能面临服务宕机的数据丢失问题。因此我们可以使用消息队列
基于List结构模拟消息队列
消息队列(Message Queue),字面意思就是存放消息的队列。而Redis的list数据结构是一个双向链表,很容易模拟出队列效果。
队列是入口和出口不在一边,因此我们可以利用:LPUSH结合 RPOP、或者 RPUSH 结合 LPOP来实现。
不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。
因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。
基于List的消息队列有哪些优缺点?
优点:
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息有序性
缺点:
- 无法避免消息丢失
- 只支持单消费者,没有办法把一条消息给很多消费者
基于PubSub的消息队列
Pubsub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
SUBSCRIBE channel[channel]:订阅一个或多个频道PUBLISH channel msg:向一个频道发送消息PSUBSCRIBE pattern[pattern]:订阅与pattern格式匹配的所有频道
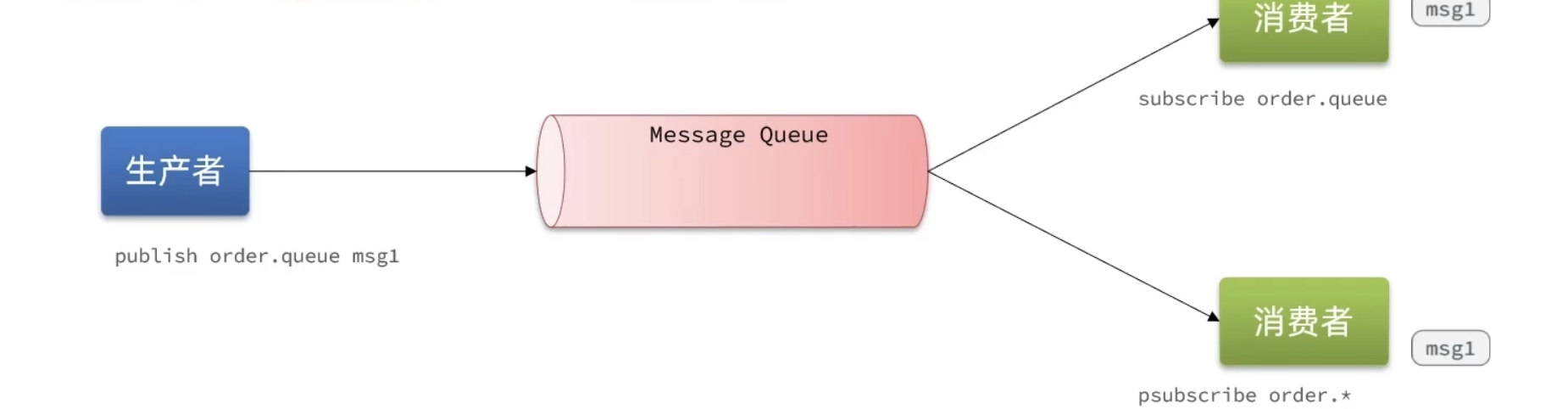
上边的消费者订阅 order.queue,下边的消费者订阅 order.任意
基于PubSub的消息队列有哪些优缺点?
优点:
- 采用发布订阅模型,支持多生产、多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
基于Stream的消息队列
Stream 是 Redis 5.0引入的一种新数据类型,可以实现一个功能非常完善的消息队列。
发送消息的命令:xadd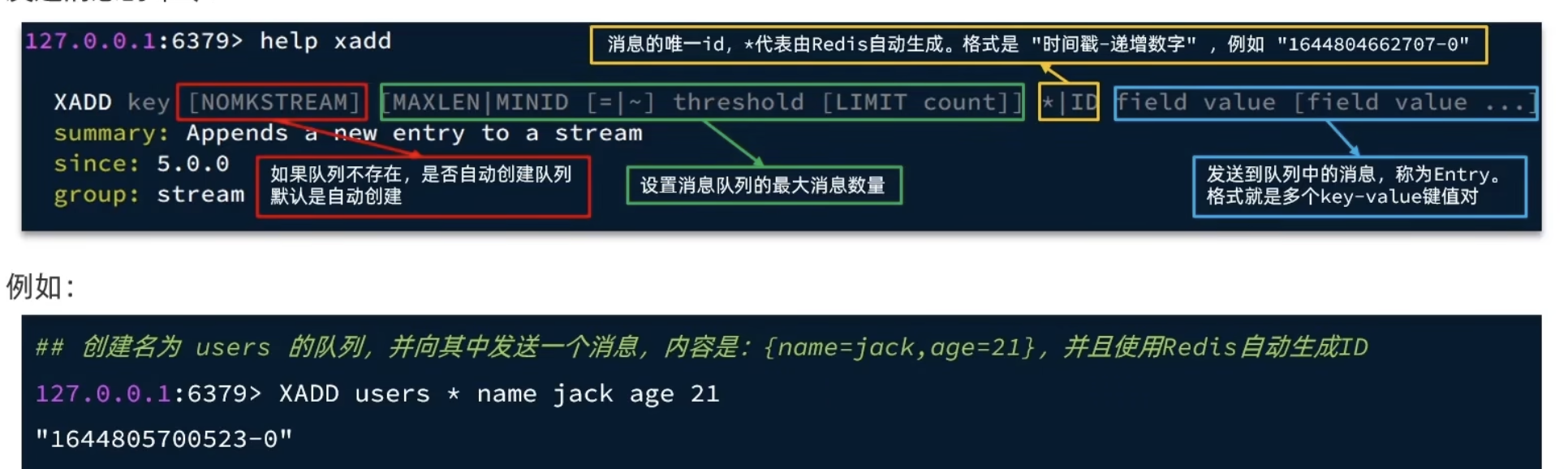
接收消息的命令:xread
STREAM类型消息队列的XREAD命令特点
优点:
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
缺点:
- 有消息漏读的风险
基于Stream的消息队列-消费者组
特点
- 消息分流
队列中的消息会分流给组内的不同消费者,在一个组中,不会出现一条消息被多个消费者消费的情况,从而加快消息处理的速度。
- 消息标示
消费者组会维护一个标示,记录最后一个被处理的消息,哪怕消费者宕机重启,还会从标示之后读取消息。确保每一个消息都会被消费。这个消息标示也避免了消息漏读。
- 消息确认
消费者获取消息后,消息会处于 pending 待定状态,并存入一个 pending-list 中。当消息被处理完成后,需要通过 xack 来确认消息,这样,消息才会被标记为已处理,然后从 pending-list 中移除。
Stream消费者组模式相关命令
从消费者组中读取消息:
消费者监听消息的基本思路:
1 | while(true){ |
消费者持续从Stream消息队列中提取尚未被消费的消息。如果没有检索到消息,消费者将进入下一个循环,再次尝试获取消息。一旦成功获取到消息,消费者将进行消息处理,并在处理完成后确认消息(ack)。如果在处理消息的过程中遇到异常,则进入catch代码块,此时将对挂起列表(pending-list)中的消息进行再次处理,并同样进行确认。如果再次处理时仍然出现异常,系统将记录相关日志,并可能需要人工干预。随后,消费者将继续循环,直到从挂起列表中无法再取出任何消息为止。这样的处理机制确保了消息在被成功处理前不会从系统中丢失,同时也保持了处理流程的连续性。
STREAM类型消息队列的XREADGROUP命令特点:
消息可回溯
可以多消费者争抢消息,加快消费速度
可以阻塞读取
没有消息漏读的风险
有消息确认机制,保证消息至少被消费一次
总结
| List | PubSub | Stream | |
|---|---|---|---|
| 消息持久化 | 支持 | 不支持 | 支持 |
| 队集读取 | 支持 | 支持 | 支持 |
| 消息堆积处理 | 受限于内存空间,可以利用多消费者增加处理能力 | 受限于消费者缓冲区 | 受限于队列长度,可以利用消费者组提高消息处理速度,减少堆积 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |


