缓存穿透、缓存雪崩与缓存击穿
缓存穿透、缓存雪崩与缓存击穿
Jaron缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
解决办法:
- 缓存空对象
当查找的数据在数据库中不存在时,可以将这个非空的空结果缓存起来,并设置较短的过期时间。这样,当再次查询相同的数据时,可以直接从缓存中获取到这个空结果,从而避免对数据库的访问。需要注意的是,这种方法可能需要适当处理缓存的对象,以防止缓存过多无用数据。
优点:实现简单,维护方便
缺点:
- 额外的内存消耗
- 可能造成短期的不一致
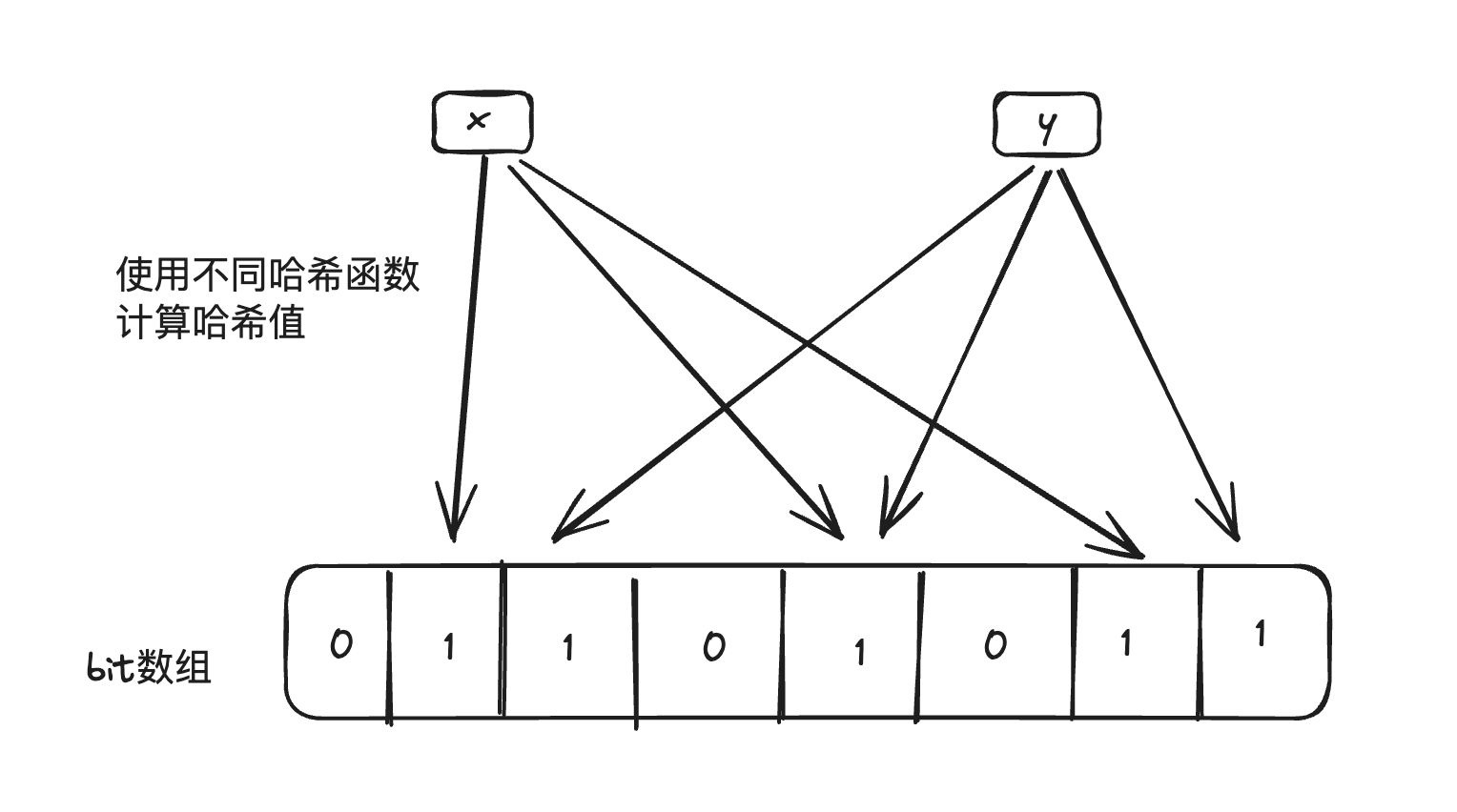
- 布隆过滤
布隆过滤器是由布尔逊(Burton Howard Bloom)在1970年提出的一种空间效率很高的概率型数据结构,用于测试一个元素是否是一个集合的成员。它的优点是空间和时间效率都非常高,缺点是有一定的误识别率和删除困难。
布隆过滤器的工作原理
- 初始化:
• 布隆过滤器本质上是一个大型的位数组和几个哈希函数。开始时,位数组中的每一位都被设置为0。
- 添加元素:
• 当我们要添加一个元素到集合中时,该元素会被哈希函数处理,得到几个哈希值。
• 这些哈希值对应于位数组中的位置,我们将这些位置上的位都设为1。
- 成员查询:
• 当我们需要检查一个元素是否属于这个集合时,我们将这个元素通过相同的哈希函数处理,得到相应的哈希值。
• 查看位数组中这些哈希值对应的位是否都是1
• 如果所有对应的位都是1,那么这个元素可能在这个集合中(存在误判的可能)。
• 如果任何一个位不是1,则该元素绝对不在集合中。
缓存雪崩
缓存雪崩是指在缓存层面发生的问题,当大量的缓存项集中在同一时间失效或缓存服务完全宕机时,所有的请求都会直接打到数据库上,这会导致数据库压力骤增,进而可能引起数据库崩溃,从而影响到整个系统的稳定性和可用性。
缓存雪崩的主要原因有:
缓存同一时间大规模过期:如果缓存中大量数据集中在同一时间过期,那么在这些缓存过期的瞬间,对这些数据的查询就会直接访问数据库,而不是缓存。
缓存服务宕机:如果缓存服务器发生故障或重启,原本应该访问缓存的请求都会转向数据库。
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(通常是热点数据),在并发访问高的情况下,突然失效(例如过期),导致所有的请求都落到数据库上,可能会对数据库造成过大压力。
常见的解决方案有两种:
互斥锁
逻辑过期(永不过期)
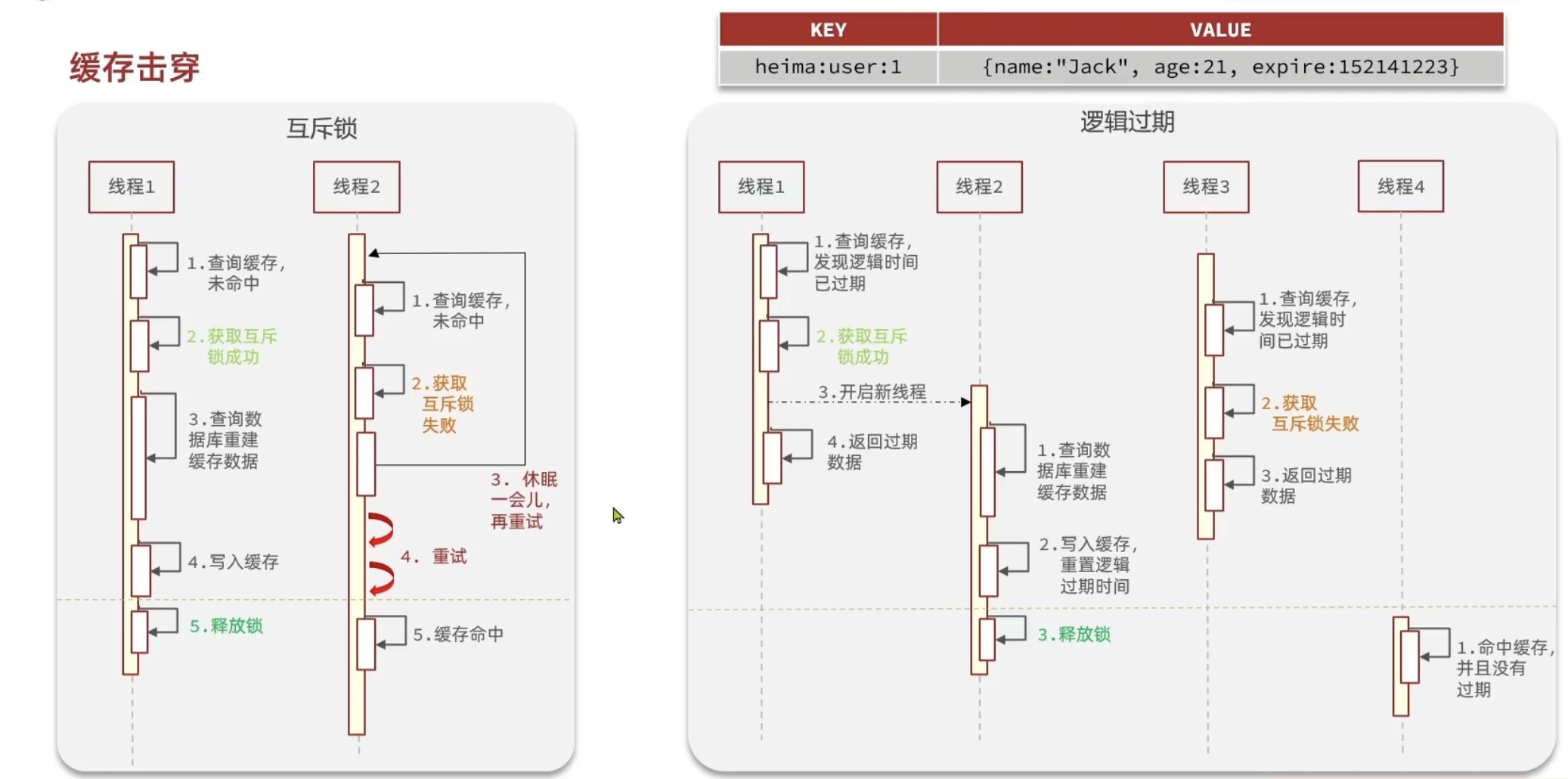
互斥锁
优点:
减少数据库压力:通过互斥锁确保对于同一个缓存失效的键,只有一个请求查询数据库并更新缓存,其他请求等待缓存更新完成后再访问缓存,从而避免对数据库的大量并发访问。
数据一致性:互斥锁可以保证在任何时候,对于任何给定的键,缓存中至多只有一个线程在进行数据更新,这有助于维护数据的一致性。
缺点:
延迟问题:如果缓存键非常热门,多个并发请求可能需要等待锁释放,这会增加用户的等待时间。
死锁风险:在某些实现中,如果不当使用锁机制可能会引发死锁,特别是在分布式环境中。
逻辑过期
逻辑过期是指设置缓存项不真正过期,而是通过逻辑判断决定何时更新缓存。
优点:
避免高峰压力:即使数据已经“过期”,缓存仍然可以提供旧值,避免所有请求直接访问数据库,可以平滑地处理数据更新,避免高峰时段的数据库压力。
用户体验:用户不需要等待数据被更新,可以立即获取响应,尽管是旧数据。
缺点:
数据时效性问题:使用逻辑过期策略可能会导致用户看到的是旧数据,如果业务对数据实时性有较高要求,这可能是一个问题。
资源消耗:虽然避免了直接的数据库访问压力,但后台更新线程需要定期运行,也会消耗系统资源。


